
When the Act of Anne established the first statute law on copyright in 1710, it neglected to discuss the legal status of works that derived from, but did not entirely replicate, earlier publications. Translations, abridgments, and adaptations soon posed new questions on the acceptable uses of extant publications, and each became the center of intense legal deliberations in English courts. The judges who presided in these cases disambiguated a wide range of derivative literary forms, and offered influential rulings on the legal status of each. Historians have paid a great deal of attention to these cases, not least because they established the foundations of “fair use” policies still present in many legal systems. While researchers have documented the ways these early copyright cases affected particular authors from the period, however, there is little scholarship on the systematic ways in which rulings on derivative works affected the eighteenth-century book market. The study below attempts to fill this void by analyzing macroscopic trends in derivative literary forms across 200,000 works from the eighteenth-century English canon.
Statutory Copyright and Derivative Publications
The 1710 Act of Anne granted publishers a statutory guarantee that they alone would be the sole legal publishers of works for which they had acquired the copyright. However, the statute did not clarify exactly what this right entails. In particular, the statute did not discuss the ways courts should treat works that derived from, but did not entirely replicate, a work under copyright. When eighteenth-century copyright holders discovered that others had adapted language and images from their publications, they took to the courts to learn just what forms of borrowing would be permitted under the new copyright regime. In a series of highly-influential cases, English authors and publishers forced the courts to clarify the boundaries between legal and illegal uses of published print records. These cases, some of which we will detail below, ultimately defined a thin line between illicit thefts and agreeable adaptations.
Many researchers readily acknowledge these cases created the foundations of modern “fair use” law. There is little consensus, however, on the ways these rulings affected the production of derivative publications in the eighteenth century [Sag 1373]. In the case of literary abridgments—the most prominent form of derivative work from the period—for example, David Vaver argues that British publishers “frequently abridged one another’s works” long after the 1710 Statute of Anne was enacted [Vaver 225], while William St. Claire identifies “a clamp-down on abridgments” from 1600 until the 1774 Donaldson v. Beckett decision, after which St. Claire argues “a sudden flood” of derivative works rippled through the English book market [St. Claire 72].
These disagreements are exacerbated by the fact that few have attempted systematic studies of derivative works and their relationship to eighteenth-century copyright law. Many researchers have observed this lack in the scholarship. Art historian David Kunzle, for example, has lamented that “there is … no study of artistic piracy in Europe” during the eighteenth century [Kunzle 311]. Likewise, legal historian Isabella Alexander has observed that book historians lack a systematic study of textual abridgments during the period [Alexander 1363]. William St. Claire, one of few to pursue a corpus-driven analysis of the eighteenth-century book market, has also noted the need for a data-driven study of the new copyright regime’s effect on the book market. “I am unaware,” St. Claire writes, “of any published quantitative or economic analysis of the effects of the changing intellectual property regime on texts, prices, access, and readerships” [42]. The present study attempts to fill this gap by studying trends in derivative publications within a corpus of 200,000 works published in eighteenth-century England.
Derivative Publications after Gyles v. Wilcox
In the sixteenth and seventeenth centuries, publishing was managed by the Stationers’ Company, an institution incorporated in 1557 to help the English government control blasphemy and sedition within the printing industry. Only members of the Stationers’ Company or individuals given special royal dispensation could become printers and legally publish works. Authors who wished to publish a work sold their manuscript to these printers, who generally retained the right to copy the purchased work in perpetuity [Holdsworth 843].
The English government supported this printing system by enacting a wide range of ordinances that explicitly forbade both complete and partial reprints of published works.1 Despite these restrictions, however, derivative works were evidently fairly common during the period. Indeed, the preamble to the Statute of Anne called attention to the abundance of piracies in the English book market, lamenting the fact that “Printers, Booksellers and other Persons have of late frequently taken the Liberty of printing, reprinting, and publishing … Books and other Writings, without the Consent of the Authors and Proprietors … to their very great Detriment” [8 Anne, c. 19].2
In order to prevent English publishers from continuing to reprint extant works, the Act of Anne established a new copyright regime based on statutory law. Unfortunately, as legal historian Isabella Alexander observes, the Act “made no mention of those who might print or reprint only part of a book, or who might print it in a slightly altered form” [Alexander 1362]. The few proposed bills that addressed partial reprinting were rejected, which meant case law would determine the precedent on which future rulings would depend [Ginsburg 647, Alexander 1367].
The earliest cases on derivative literary works from the period—Chiswell v. Lee (1681), Wellington v. Levi (1709), Tonson v. Baker (1710), Gibbs v. Cole (1734), Austen v. Cave (1739), Hitch v. Langley (1739), and Read v. Hodges (1740)—all ended with injunctions that prohibited the sale of the defendant’s derivative work.3 The last of these, however, anticipated a changing attitude toward derivative works that would survive in English courts to the end of the century.
In 1739, James Read published a three-volume edition of John Motley’s work The History of the Life of Peter the First Emperor of Russia. The following year, James Hodges abridged the work into a single volume published as The Life and Reign of the Czar Peter the Great. When Read sued for an injunction in Read v. Hodges, Hodges defended the legitimacy of his edition on four grounds; namely that his edition cost him great time and money, that his edition was aimed at a “meaner” audience than Read’s publication, that he varied every passage he copied from Read’s edition, and that Read’s edition itself contained 108 pages copied with little variation from Friedrich Weber’s 1722 work, The Present State of Russia [Deazley 82-3]. Hodges’s argument was initially effective, as the chief presiding judge Lord Hardwicke dissolved the preliminary injunction against Hodges. Later the same day, however, Hardwicke heard additional arguments from both sides and reinstated the injunction, which remained in place at trial’s end [Deazley 796, Alexander 1373].
Lord Hardwicke’s initial position in Read v. Hodges anticipates the watershed decision he would deliver the following year while presiding over the landmark case Gyles v. Wilcox (1741). The case arose after John Wilcox hired an author to abridge The History of the Pleas of the Crown, which the English bookseller Fletcher Gyles had published in 1736. Gyles sued for an injunction, but during the course of the trial Wilcox’s abridgment was recognized as an original copyrightable work and Gyles was ultimately denied injunctive relief. In his official remarks on Gyles v. Wilcox, Lord Hardwicke famously argued: “Where books are colourably shortened only, they are undoubtedly within the meaning of the act of Parliament, and … a mere evasion of the statute, and cannot be called an abridgment. But this must not be carried so far as to restrain persons from making a real and fair abridgment, for abridgments may with great propriety be called a new book, because not only the paper and print, but the invention, learning, and judgment of the author is shewn in them, and in many cases are extremely useful” [26 English Reports 490].4 Often cited as the foundation of future fair use decisions, Hardwicke’s argument in Gyles v. Wilcox ushered in a new era in English copyright law, one in which authors and publishers could consistently defend the legality of derivative publications.
While derivative works before Fletcher v. Wilcox were consistently denied legal standing, those afterwards were often granted legal standing. Following the Gyles decision, a string of influential cases—including Cogan v. Cave (1743), Dodsley v. Kinnersley (1761), Strahan v. Newberry (1774), Sayer v. Moore (1785), Carnan v. Bowles (1786), Harrison v. Hogg (1794), Cary v. Longman and Rees (1801), Wilkins v. Aikin (1810), and Whittingham v. Wooler (1817)—all ultimately denied the plaintiff’s petition for an injunction against a partially derivative work. This transformation in legal philosophy was to have long-lasting consequences, for as the legal historian Simon Stern has noted, English courts continued to recognize derivative publications as original, copyrightable works until well into the nineteenth century [Stern 11].
While scholars have recognized that Gyles v. Wilcox introduced a “fair use” interpretation of derivative works into English copyright law, they have disagreed about the ways this shift affected authorial practices during the period. Some researchers, such as the prominent legal historian Ronan Deazley, have argued that judges who recognized derivative works as original, copyrightable works after Gyles v. Wilcox encouraged a “proliferation of review articles, literary ‘epitomes’, abridgments, and ‘detached episodes’” [Deazley 4]. Others, such as William St. Claire, argue instead that “literary anthologies and abridgments suddenly disappeared in 1600 and [were] suddenly revived in 1774” following the Donaldson v. Beckett (1774) ruling [St. Claire 80]. Hitherto, researchers have lacked corpus-driven evidence with which to evaluate these competing histories of imitative publications. In what follows, the methods used to generate one body of evidence with which to pursue this debate are discussed.
Identifying Derivative Texts: Data and Methods
To measure the rate of derivative publications across the course of the eighteenth century, the present study leverages the Eighteenth-Century Collections Online (ECCO) databases I and II, a set of 182,765 titles published between 1700 and 1800 described above. Two aspects of the ECCO dataset had a particularly strong influence on the methods used to identify text reuse in the present study.5 The single most influential aspect of this dataset was the sheer size of the corpus. The text dataset on which the analysis below was run contains 182,765 titles with more than 32 million pages of text. To compare each of these titles to each other would mean making over 16 billion comparisons. Even if each comparison took only one second, this computation would still take over 500 years to complete. To make this computation more tractable, the analysis below transformed each document into a set of many “signatures” (detailed below), where each signature represents the content of a small portion of a document. Using this signature-based approach allowed a supercomputer to search for instances of text reuse between all documents in the dataset within roughly one month’s time.
The second major factor in the method selection was the variable text quality of the input documents. The ECCO database is especially prone to rough OCR, as the books were photographed at scale many years ago with poorer camera technologies, and contain non-standard spellings, outdated font styles, and forgotten characters such as the long ∫—all of which confounded the OCR model used to transform page images into parsable text:

To discover text reuse in this large corpus with non-standardized spelling and poor OCR, I implemented the following workflow. First, each sequence of 14 consecutive words was identified in each document, and every fourth window was retained for analysis. All unique three-character sequences were extracted from each of these windows, and each of these character sequences was used to build a set of 256 hashes that represent the content of the given window.6 All text windows that shared a sequence of four consecutive hash values were then compared for similarity using a variant of the Ratcliff/Obershelp algorithm, and the resulting verified matches were saved in a database for subsequent analysis.
The process described above discovered 43 million text pairs within ECCO that contained one or more shared passages.7 The vast majority of these text pairs, however, shared only one or two isolated epigraphs, aphorisms, or random character sequences. To focus on more bona fide instances of text reuse, additional filters and clustering operations were applied to this initial set of matches. In the first place, text pairs that shared fewer than 100 matching windows (roughly one page’s worth of shared text) were removed from the dataset. Next, all editions of each published title were clustered into abstract groupings. These abstract groupings helped ensure that multiple editions of a work would not generate duplicate matches with another work. These groupings also helped ensure that given a pair of documents with shared text, the earliest printed edition of each could be consulted in order to determine which work was published first. Finally, self-similar texts by each author were clustered together so works published under various titles could be mapped to the first year in which the given work was published.
These filtering and clustering operations were highly imperfect. In the first place, the metadata available in both the English Short Title Catalogue and the Eighteenth Century Collections Online database are riddled with shortcomings. The individuals who hand-keyed the ESTC metadata—the bibliographical backbone of ECCO—relied heavily on the title pages of works from the period, which are known to be quite faulty. For example, relying upon spurious title page information, ECCO attributes over half a dozen specious works to William Shakespeare, none of which are accepted by modern scholarship.8 Publication dates in the ECCO and ESTC metadata are also quite often unreliable; when confused about the publication year of a given work, editors of both databases often assigned the given work to the most likely decade, resulting in publication spikes every 10 years with each database. One printing of Daniel Defoe’s Moll Flanders (N504959), for example, lists an imprint year of “ca. 1760,” and simply notes “Date conjectured by cataloguer.” These metadata challenges should temper any strident claims one might wish to make about the results detailed below.
Derivative Texts in the Eighteenth Century
The methods discussed above generated a dataset of 130,000 pairs of ECCO titles that each contain 100 or more passages of highly similar text. These matching passages come in a wide variety of forms, though most come from rather obscure corners of the eighteenth century printing world. Consider for example the recipe for “Turkey-a-la-daube, to be sent up cold” in Elizabeth Raffald’s 1782 Experienced English Housekeeper (left), one of many recipes that Mary Cole lifted from Raffald for her own 1789 Cookery and Confectionary in All Their Branches (right):


Blatant plagiarism of the sort pictured above is only one of many forms of text reuse captured in the dataset. Lyrics of popular songs, tables of logarithms, recitations of common law, and countless other elements of shared public discourse also fill the database, a small sample of which can be viewed below:
When viewed in the aggregate, instances of text reuse appear to grow in frequency quite rapidly in the latter half of the century. The figure below displays the raw counts of eighteenth-century publications that contain at least 100, 200, and 500 matching passages (respectively) with other works from the period:
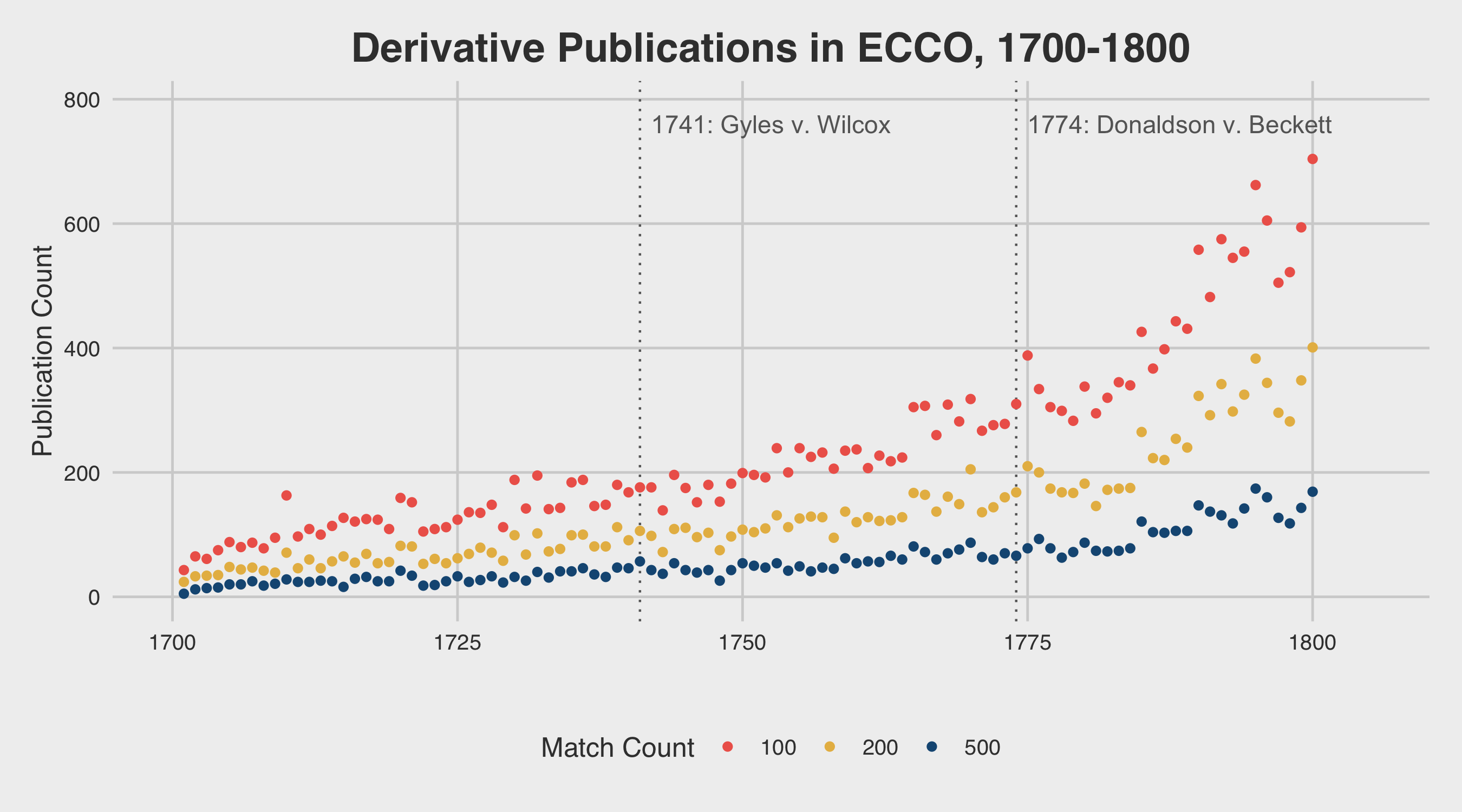
As we have seen above, however, the number of titles printed annually also grows quite rapidly at the end of the eighteenth century. In order to properly evaluate the rate of change in derivative printing practices, it is therefore important to “normalize” the raw counts above by dividing each by the total number of titles published in the given year. Normalizing the derivative text counts in this way results in the figures displayed below:
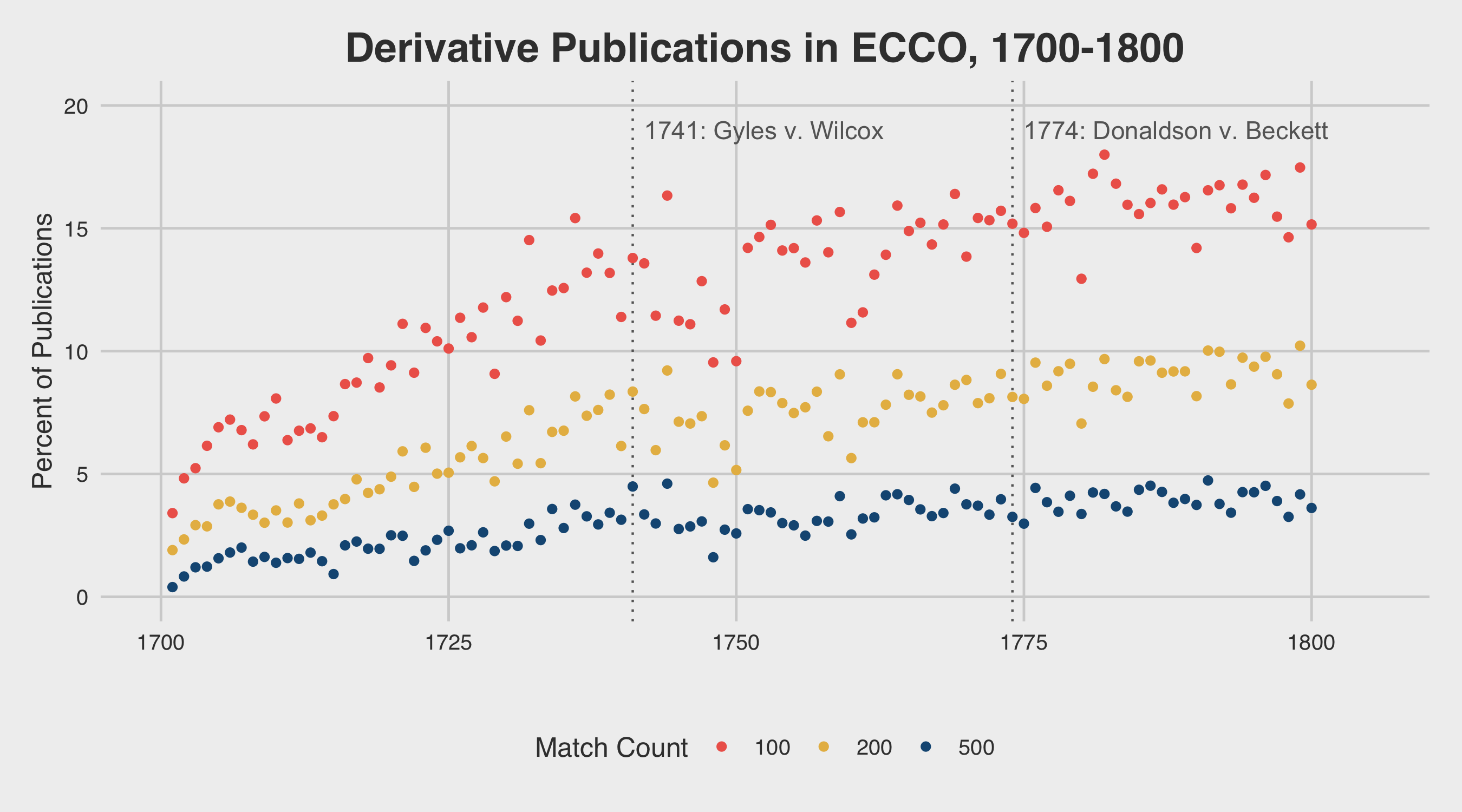
Examining this plot, one finds that derivative text rates increase rapidly in the early decades of the century, then slowly approach an equilibrium point in the later decades of the century. Rather than a “sudden flood” of derivative works after the Gyles v. Wilcox or Donaldson v. Beckett cases, one finds instead that authors and printers steadily continued to reuse more and more text material from earlier publications.
In short, the data presented above suggests authors and publishers were less influenced by the legal transformations of the eighteenth century than scholars previously believed. Turning to the history of image reuse within the period in what follows, we will observe a similar trend, and will set the stage for a fascinating case study that remixes both text and images from contemporary works in innovative ways.
The Engraving Act and Early Copyright in Images
While printed materials acquired statutory protection in the Statute of Anne (1710), engravings, prints, and other visual art did not gain statutory protection until the Engraving Act (1735). Often identified as the second major piece of British copyright law, the Engraving Act was the result of a series of petitions organized by William Hogarth and other engravers, who believed visual artists and designers deserved the same copyright protections that authors had acquired in the Statute of Anne.
To secure copyright protection for his own artistic works, the prominent printer William Hogarth organized a petition to the House of Commons, where he lamented the fact that “divers Printsellers … have, of late, too frequently taken the Liberty of copying, printing, and publishing, great Quantities of base, imperfect, and mean, Copies and Imitations thereof; to the great Detriment of the Petitioners” [364]. House members recognized the validity of Hogarth’s concerns and soon passed the 1735 Act for the Encouragement of the Arts of Designing, Engraving, and Etching [8 Geo. II, c. 13], often referred to as “Hogarth’s Act.” This Act provided a 14 year, fixed-duration copyright protection for new visual artworks, though the 1766 Engraving Copyright Act [7 Geo. III, c. 38] doubled the term of protection to 28 years, and a third 1777 Engraving Act [17 Geo. III, c. 57] allowed proprietors to claim damages suffered from unlicensed reproductions of their works [Shortt 108].9
In 1739, Hitch v. Langley became one of the first copyright cases over image reproductions following the enactment of the new statute.10 The case’s plaintiff, Charles Hitch, was a member of the London Conger—the small and elite group of wealthy publishers that ruled the English book market—who had acquired the copyright for James Gibbs’ Book of Architecture (1728) and Rules for Drawing the Several Parts of Architecture (1732). Hitch demonstrated that the defendant Batty Langley had “printed coppyed published and sold great parts of the said books” without authority, including fourteen prints from Gibbs’ works, and was granted an injunction preventing Langley from reprinting his work or any part thereof [Alexander 1370, Deazley 80].
While several early cases on derivative prints ended with similar injunctions, Sayer v. Moore (1785) established a watershed precedent for fair use rulings in the visual arts by recognizing a defendant’s derivative prints as distinct copyrightable works. Sayer v. Moore revolved around sea charts the defendant, maritime publisher John Hamilton Moore, included in his New and Correct Chart of North America [Skelton 208]. The plaintiff, Robert Sayer, alleged Moore pirated these charts from works for which he held the copyright, and intended to obtain an injunction and £10,000 in damages. These allegations were soon confirmed when the engraver hired to produce Moore’s charts confessed “he was actually employed by the defendant to take a draft of the Gulph Passage … from the plaintiffs’ map” [Monthly Review 48]. Later in the trial, however, several witnesses demonstrated that Moore’s map had contributed a number of vital corrections to Sayer’s print, and were far less dangerous to sailors by virtue of these revisions. These improvements would have a significant effect on the ultimate verdict and the future of English copyright law.
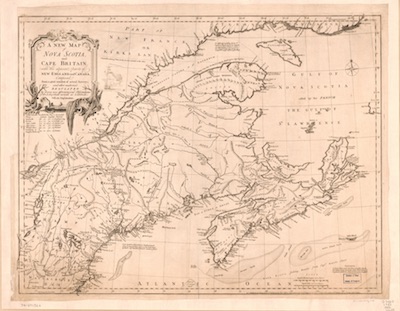

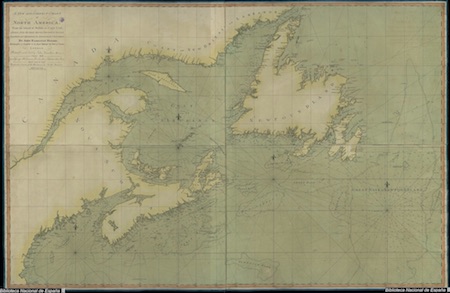
Lord Mansfield, the lead judge in Sayer v. Moore, recognized the importance of the case’s outcome. In his official remarks on the case, Mansfield noted: “The rule of decision in this case is a matter of great consequence to the country. In deciding it we must take care to guard against two extremes equally prejudicial; the one, that men of ability, who have employed their time for the service of the community, may not be deprived of their just merits, and the reward of their ingenuity and labour; the other, that the world may not be deprived of improvements, nor the progress of the arts retarded” [49]. When striking this delicate balance in the case of publications based on facts, Mansfield continues, one should not punish works for their similitude to antecedents, as doing so would prevent historians and lexicographers from describing the events and words that were described in earlier works. To find a defendant guilty of infringing another’s copyright, Mansfield concludes, “there must be such a similitude as to make it probable and reasonable to suppose that one is a transcript of the other, and nothing more than a transcript” [49]. Because Moore’s maps improved Sayer’s, and were therefore more than a mere “transcript” of the plaintiff’s work, the jury dissolved Sayer’s injunction and found in favor of Moore.
Just as Gyles v. Wilcox established a precedent for fair use rulings in derivative texts, Sayer v. Moore created a precedent for fair use rulings in derivative images. Following Sayer v. Moore, a number of cases—including Steel v. Moore (1789), Harrison v. Hogg (1794), and Wilkins v. Aikin (1810)—observed the fair use precedent and recognized derivative images as original, copyrightable works. While scholars now recognize the court’s increased tolerance for derivative images in the final decades of the eighteenth-century, however, little is known about the extent to which these fair use rulings impacted the production or distribution of visual imagery during the period. The following section describes the methods used in the present study to pursue this question.
Identifying Derivative Images: Data and Methods
Image data for the analysis below was collected from page scans in the Eighteenth Century Collections Online (ECCO) database. As we noted above, the ECCO database contains page scans from 182,765 works published between 1700 and 1800, or roughly 60% of the known titles published during the century. Gale Cengage, the creator of the ECCO database, identified the subset of page scans that contain maps, engravings, and other image content, which allowed a simple algorithm to extract the images from the page scans in which they were embedded. The resulting dataset contained 260,000 images from across the century:

Matches between the images in this corpus were discovered via the following pipeline.11 Each image in the dataset was first processed using the Inception convolutional neural network, which was designed to take an image as input and produce a text label for the image as output [Szegedy 2014]. Instead of retrieving a text label for each image in ECCO, however, the penultimate layer of weights from the network was extracted instead. This allowed each image in the dataset to be represented by a 2048 dimensional vector (or list of numbers with 2048 elements). These vectors were then used to identify the 20 images most similar to each image in ECCO via an “approximate nearest neighbors” tree constructed with random projections. These 20 nearest neighbors for each input image were later used to identify matching images with which to train a machine learning classifier, and eventually to identify the set of potential matches for each image, as described below.
Collecting the set of matching and non-matching image pairs from the set of 20 nearest neighbors for each image in ECCO was a slow and surprisingly difficult task. In the first place, ECCO contains book plates and other materials that were added to the collection’s volumes after their initial publications, and these images needed to be removed from the dataset during the course of the analysis. For example, a number of ECCO volumes contain an “ex libris” label from Marjorie Moon’s library:

Even setting these spurious images aside, however, the genuine period images captured in ECCO posed many challenges. In the first place, the ECCO page scans were photographed with uneven lighting, so two editions of the same work could contain an identical illustration that appears quite different due to the images’ varying exposure rates. Consider the same illustration from the 1737 (left) and 1782 (right) editions of Elizabeth Blackwell’s Curious Herbal:


Images that span multiple pages in ECCO also posed challenges for analysis. These multi-page images are represented by two physical images that together comprise a single logical image. In a number of cases, however, ECCO page scans combine images from two consecutive pages into a single physical image. On the left below are two consecutive physical images from Lorenz Heister’s 1748 General System of Surgery (left) combined into a single page scan in the 1763 edition (right):



In addition to variable exposure rates and multi-page scans, some illustrations were missing whole sections of the original image altogether. These cases made it seem as if someone had cut out a region of the original page with scissors. Consider for example the image pair below from the 1791 (left) and 1793 (right) editions of John Gifford’s History of France:


Even in the absence of these visual impediments, however, it can be fundamentally difficult to determine whether one illustration appears to derive from another. There are many cases where two images in the ECCO database are remarkably similar but non-identical, as in the case of the pair of illustrations below from George Wilson’s 1703 Compleat Course of Chymistry (left) and William Lewis’s 1746 Course of Practical Chemistry (right):


Image pairs such as the one above were considered a match if one image contained substantial elements from the other more or less unchanged. This meant that a detailed heraldic shield, for example, would be counted as a match for another image that contained the same shield among other shields.
In short, the guiding principle in determining whether two images matched was the probability of “simultaneous discovery”—if it seemed reasonable to believe a pair of images such as the alchemical illustrations above could have been produced by two artists who had no notion of each-other’s work, the image pair was marked a non-match. If on the other hand it seemed reasonable to believe one of the artists in the pair had seen the plates or prints of the other image, the pair was marked a match. Using this reasoning, 500 matching and non-matching image pairs were selected as inputs to be fed to a machine learning classifier. These selected matches contained examples of identical and near identical matches, as well as image pairs with different exposures, orientations of picture content (landscape and portrait), rotations of camera equipment, croppings of image content, and size of image content.
Several similarity measures were next computed for each of these hand-selected image pairs. Three image similarity metrics—Scale Invariant Feature Transform (SIFT) similarity [Lowe 1999], perceptual-hash similarity [Wong 2002], and average-hash similarity—were computed through analysis of the images themselves, and the similarity of the two pages of text before and after the image was measured using a Jaccard similarity measure on a simple bag of words model. The results of these similarity measures were then fed to an SVM classifier, which used the similarity scores and the fact that a given image pair was a match or non-match to learn how to discriminate between matches and non-matches. The “decision boundary,” or imaginary line of demarcation between matching and non-matching image scores, was then tuned so the classifier would only identify a pair of images as a match if the model was 90% certain or greater that the pair truly was a match. This helped remove many false matches from the results, but also meant that the model would identify some true matches as non-matches.
After this training step, every image was paired with each of its 20 most similar images and fed to the classifier, which identified the image pair as a match or non-match using the features described above. This produced a dataset of a quarter million distinct matching image pairs, many of which were reprints of an image across several editions of a title. These matching image pairs were then clustered using a “connected components” algorithm such that if A matched B, and B matched C, then A and C would also be identified as matches. The result of this clustering operation served as the foundation for the analysis below.
Derivative Images in the Eighteenth Century
The analysis above yielded 35,000 groups of images that had been printed two or more times. A small sample of these groups is available below:
The majority of these matching image groups came from various editions of a single work. In most cases, the publisher of the reissued title simply reprinted the plates from the first edition unchanged, yielding multiple editions of a single illustration in a cluster. Consider the dozen editions of George Anson’s Voyage Round the World below, each containing the same map of the California coast, with slightly different cropping due to the vagaries of ECCO page scans:









Other printers, however, continued to revise their image selections as they released subsequent editions of a work. Arthur Bettesworth, for example, selected new skeleton images for each of the 1730 (left), 1735 (center), 1738 (right) editions of Richard Johnson’s Seven Champions of Christendome:


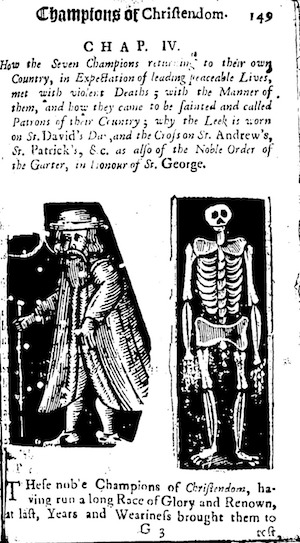
Both of the volumes above contain images that were reprinted in subsequent editions of a single work. More interesting cases are those in which an image is printed in multiple distinct titles. To examine this latter form of image reuse, the set of 35,000 matching image groups discussed above was filtered down to the subset of matching images that were published in two or more distinct titles. This filtering operation yielded just over 2,000 volumes that reprinted images from earlier works, distributed throughout the century as follows:

While it appears as if image reproductions increased at the end of the eighteenth century, this evident trend is merely an artifact of the increasing volume of images produced during the closing decades of the century. If one controls for the growing rate of image production, however, image reprinting rates remain fairly constant across the period.
In sum, just as there was no “sudden flood” of text reprints in the wake of either the Gyles v. Wilcox (1741) or Donaldson v. Beckett (1774) decisions, one finds no great inflection point within the history of eighteenth-century image reprints. On the contrary, the evidence presented above suggests that volumes containing derivative images were printed at a roughly constant rate throughout the eighteenth century. This is fairly remarkable, as the eighteenth century was home to several prolific pirates, some of whom can be studied more closely with the results of the analysis discussed above. To focus on only one example, we turn now to one of the great printer barons of the eighteenth century: John Hamilton Moore.
John Hamilton Moore’s Pirate Press
Born in a small village outside Edinburgh, John Hamilton Moore (1738-1807) completed his education and enlisted as a cadet in the English Royal Navy, where he began to cultivate a lifelong passion for maritime travel and adventure. Upon receiving his discharge from the Navy, Moore established himself as a teacher in Hounslow and began writing textbooks on navigation. After publishing a series of influential works—including a breakout hit The Practical Navigator, which ran to twenty editions [Skelton 209]—Moore moved to London around 1780 to set up shop as a publisher of nautical books and charts. It wasn’t long, however, until Moore’s publishing practices led him into legal trouble.
Soon after publishing his first chart, New and Correct Chart of North America (1784), Moore was accused of piracy in Sayer v. Moore (1785). During that case, as we saw above, Moore’s engraver confessed to having drawn upon the plaintiff Robert Sayer’s maps, but Moore’s improvements of Sayer’s work were found sufficient to warrant his chart a new work that did not infringe upon Sayer’s copyright.
Not long after Sayer v. Moore, Moore was once again accused of plagiarism in Steel v. Moore (1789), during which the hydrographer David Steel alleged that Moore’s chart of “the East Coast of England, including the Navigation from the South Foreland to Flamborough Head” had been pirated from two charts of his own [Moore 1794]. John Stevenson, a friend of Moore’s, prepared a list of 106 points in which Moore’s map differed from Steel’s, and helped reveal numerous errors and omissions in Steel’s map that had been remedied in Moore’s. Steel’s counsel left his client nonsuited, and forced Steel to reimburse Moore’s legal expenses.
Some few years later in Heather v. Moore (1798), the maritime publisher William Heather claimed Moore had copied his “Chart of the Coasts of France Spain & Portugal.” Heather’s attorney showed that Moore had made a servile copy of Heather’s work, and that “Mr Moore had, through his negligence, omitted islands, rocks, and shoals by wholesale, which omissions … would often prove fatal to the lives of Mariners” [Moore 2]. Moore admitted his chart to be a copy of Heather’s map “verbatim et literatim,” but alleged Heather had copied an earlier chart Moore himself had published. After failing to convince the jury of this claim, Moore was ordered to destroy the plates from which his maps were printed and forfeit all profits derived therefrom to the plaintiff.
While Moore emerged from these legal battles with a reputation for piracy, he had in fact grown accustomed to reprinting the work of others years before his first court case. Even in his 1778 New and Complete Collection of Voyages and Travels (N4909), one finds a treasure trove of text and images meticulously adapted from works already circulating in the book market.
At its core, Moore’s Voyages and Travels is a series of abridged exploration narratives with small contributions of original text peppered throughout. In some places, Moore embellishes his source materials, reworking an earlier author’s language to paint a scene slightly differently. In his depiction of the “Supreme Portal” within the emperor of China’s palace (left), for example, Moore reworks both Thomas Astley’s 1747 depiction of the scene in his Collection of Voyages and Travels (right) and the original scene in Gabriel de Magalhães’s 1688 New History of China:


Elsewhere in his Voyages and Travels, Moore weaves source material into his own exposition so tightly it becomes difficult to tell when his text is original and when it is adapted from an earlier source. For example, in his abridgment of Jonathan Carver’s Travels Through the Interior Parts of North America, Moore translates Carver’s first-person voice into the third person and periodically interjects original prose, making it difficult to discern when Moore is reprinting Carver:


Astley and Carver are only two of many authors who share text with Moore’s Voyages and Travels. Indeed, within Moore’s work, one finds echoes of Samuel Johnson, Captain Cook, Joseph Addison, Tobias Smollett, and a wide range of other authors from the period, both prominent and obscure. At the same time, by comparing Moore’s volume to later works from the century, one finds dozens of travel narratives that in turn adapt language and images from Moore. The interactive graphic below displays a subset of the volumes that share text with just the second volume of Moore’s Voyages and Travels. To browse the matches, use your keyboard’s left and right arrow keys to advance through the text:

In addition to abridging dozens of volumes in his Voyages and Travels, Moore also reprints great quantities of visual material from earlier works. For example, in anticipation of the map controversies that lay in his future, Moore adapts a chart of England (left) from Robert Sanders’s Complete English Traveller; or, a New Survey and Description of England and Wales (1771, center), the exact plate of which appears to have been reprinted in Sydney Temple’s New and Complete History of England (1774, right):

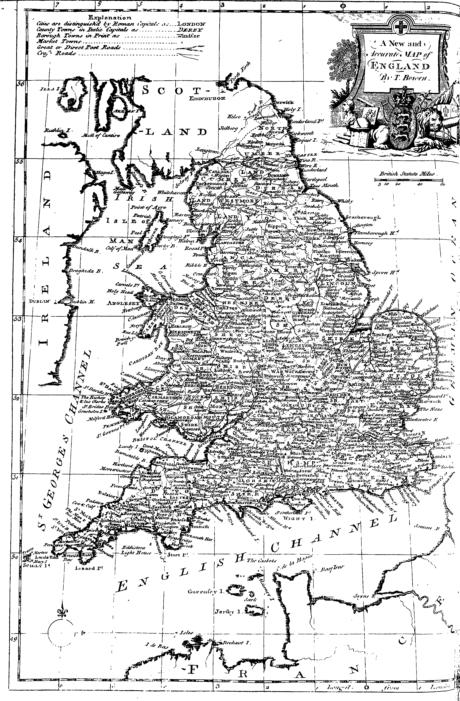

Just above Moore’s map of England, a small inscription boasts: “Engraved for Moore’s New and Complete Collection of Voyages and Travels.” This stamp of originality adorns many other prints in Moore’s volume, such as the illustration of “Various Carriages & Sledges used … during the Winter in Russia” (left), which Moore lifts from Jean-Baptiste Chappe d’Auteroche’s 1770 Journey into Siberia (right):


Some of Moore’s borrowings rework their source material quite thoroughly. In his depiction of “The Indians of North America” (top), for example, Moore combines two images from Jonathan Carver’s celebrated travel narrative Travels Through the Interior Parts of North-America (bottom), first published the same year as Moore’s Voyages and Travels:



Moore was evidently intrigued by the transformative process of combining source images, as he uses the same editorial technique elsewhere in his Voyages and Travels. In his illustration entitled “Different Ways of Travelling in the Congo” (top), for example, Moore reverses and combines two images from Thomas Astley’s 1745 General Collection of Voyages and Travels (bottom):



Elsewhere in Moore’s Voyages and Travels, one encounters images that several eighteenth-century publishers repurposed. For example, Moore’s depiction of a kangaroo is one of many that began to circulate in the wake of Captain Cook’s voyages to the South Pacific. Shown below from left to right are the kangaroos in John Hawkesworth’s Voyages Undertaken … in the Southern Hemisphere (1773), Oliver Goldsmith’s History of the Earth, and Animated Nature (1774), John Hamilton Moore’s Voyages and Travels (1778), and Thomas Bankes’s Complete System of Universal Geography (1788):




The maps and illustrations above represent only a small fraction of the materials Moore reprints in his Voyages and Travels, which is only one of thousands of works that reprint earlier textual and visual materials during the eighteenth century. Even this small sample, however, reveals new insights about the nature of eighteenth-century printing. By tracking piracies in works like Moore’s Voyages and Travels, we see firsthand the ways in which visual and textual culture circulated in the eighteenth century. The editorial transformations Moore and his contemporaries introduced into the works they appropriated reveal that authors and publishers from the period saw artistic culture as a public commons of sorts—one meant to be continually remixed into new enterprising creations.
Conclusion
Previous scholarship has debated the ways in which legal transformations in the wake of the 1710 Statute of Anne affected derivative authorial practices in the eighteenth-century book market. While some scholars have argued that derivative authorial practices continued to flourish after the enactment of the Statute of Anne, others have maintained that derivative printing practices only flourished in the aftermath of influential cases such as Gyles v. Wilcox (1741) or Donaldson v. Beckett (1774). This study provides new data-driven insights into this question, ultimately finding that text reprinting grows steadily if slowly throughout the century, while image reprinting remains roughly constant during the century. Using a small subset of the data derived during this analysis, the study above examines in particular the case of John Hamilton Moore, who was tried for piracy at least three times in the second half of the century, in order to better understand the derivative authorial practices of an ambitious pirate printer. In the end, I argue, by continuing to use computational methods to investigate the circulation of textual and visual materials during the eighteenth century, we can derive significant new insights into the practices of readers, writers, and printers from the period.
Notes
1. A number of prohibitions against partial reprinting were passed before the 1710 Statute of Anne. In 1637, the Star Chamber granted protections for “books, ballads, charts, portraiture, or any other thing” and prohibited the copying of “name, title, mark or vinnet” from these protected works [Kunzle 311]. In 1643, Parliament ordered that “no Book, Pamphlet nor Paper, nor part of such Book, Pamphlet or Paper” be printed without being first licensed and registered with the Company of Stationers [Slauter 36, Stern 5]. In 1678, the Stationers’ Company again forbade the reprinting of “any part of any Book” without consent of the book’s author, and in 1681 the Stationers’ Company strengthened this prohibition against partial reprintings in another ordinance [Alexander 1362, Alexander 161].
Despite these early prohibitions against derivative works, the English government enforced a rather inconsistent set of regulations of reprints during the period. In 1621, for example, Helen Mason was granted a royal license to abridge Foxe’s Book of Martyrs [Deazley 799], while ten years later Robert Young was denied a license to abridge the same work [Alexander 1364]. ↩
2. Citations of English statutes enacted before 1962 report the name of the sovereign, their “regnal years” (years as monarch), and “chapter number” (1-based index position of the act in the parliamentary session for the given regnal year). Thus 8 Anne, c. 19 refers to the 19th act passed in the parliamentary session held during the 8th year of Queen Anne’s rule (1710). For more information on statutory citations, see Bluebook 274. ↩
3. Most of the legal battles over copyright infringement from the period were fought in the Court of Chancery, and most followed a fairly predictable narrative. Generally a plaintiff alleged their copyright had been infringed or was soon to be infringed by a derivative work, and if their allegations seemed worthy of inspection, an injunction was immediately granted to prohibit the defendant from printing or vending the work in question [34 English Reports 886]. This injunction remained in place until the case came to hearing, at which point the defendant could attempt to convince the court that they had not infringed the plaintiff’s rights. In many cases, the preliminary injunction created at the outset of the case was enough to stop a pirate, who could not afford the time and money required to fight a proper legal battle [Bald 89].
Among the pre-1741 cases that did proceed to judgment, there were of course a number of examples that are not detailed above—including Saunders v. Tonson (1690), Burnet v. Chetwood (1721), Knaplock v. Curll (1722), Tonson v. Clifton (1722), Gay v. Read (1729), Gilliver v. Watson (1729), Motte v. Walker (1735), Baller v. Watson (1737), and Eyre v. Walker (1737)—but these cases hinged on issues other than partial reprintings of protected works. ↩
4. Citations of eighteenth-century legal cases often appear in one of two forms. Some legal citations, such as those in H. Tomás Gómez-Arostegui’s database of early English copyright cases, cite the organizational schema of the relevant archival materials within The National Archives. For example, Gómez-Arostegui’s citation for the first court proceedings in the Gyles v. Beckett case, C11/1828/27, m. 1, refers to the 27th entry within the 1828 record group (Pleadings) within the C11 record division (Court of Chancery). Using this schema, one can identify the relevant document in the National Archives.
Those without direct access to the National Archives often cite the English Reports, a 178-volume publication that contains the facts and relevant procedural information from the majority of legal cases tried in England between 1220 and 1866. The citation above, 26 English Reports 490, refers to the 490th page of the 26th volume of the English Reports, which one can access using the physical English Reports volumes or HeinOnline’s digital scans of the same.
It is important to note that The National Archives and the English Reports contain very different kinds of documents. The National Archives contains the actual manuscripts of legal documents created by legal disputants, including legal complaints, answers, and clerk records that detail the rough sequence of events in court. The English Reports, by contrast, contain just the judgment, or ruling, of cases (which is often missing from court documents in The National Archives), and are vastly more selective than The National Archives. These synopses in The English Reports were often written by wealthy barristers who had a personal interest in the law, and some are believed to be more reliable than others. ↩
5. Automatic discovery of reused text is a major field of research in engineering journals, and there are many papers on the subject. For excellent overviews of relatively recent methods, see Alzahrani 2012 and Wang 2014. For recent papers in the Digital Humanities that leverage automatic discovery of text reuse, see Bamman 2009, Mews 2010, Roe 2012, Smith 2013, Forstall 2014, and Ganascia 2014. ↩
6. These hashes were generated using the “minhash” technique introduced by Andrei Broder (Broder 1997) and documented in Mining of Massive Datasets, 3.3-3.4. All character trigram sets were hashed using the same set of 256 permutation functions, which allowed the processing to be massively parallelized. These minhash signatures collectively provide a “locality-sensitive hash” of each passage, such that the probability of two passages generating the same hash sequence is proportional to the similarity between those passages. The 14-word window size and 3-character subwindow size used as hyperparameters in the minhashing analysis described above were selected based on tests run on a corpus of sample intertextual matches, on which task they performed better than all other window size selections. ↩
8. The following titles are spuriously attributed to William Shakespeare in the ECCO metadata: The Life and Death of Thomas, Lord Cromwell (T054710), The History of Sir John Oldcastle (T054116), The Puritan (T053695), A Yorkshire Tragedy (T054137), Modern Characters (N005159), The London Prodigal (T041173), and The Students (T062209). These examples represent only a small subset of the metadata errors that plague digital databases like ECCO and the ESTC. ↩
9. There were some ad-hoc prohibitions against reprinting visual materials before the enactment of the Engraving Act (1735). In the age when monarchs granted royal monopolies for particular genres of printing, Charles II granted John Seller letters patent that “prohibit[s] and forbid[s] all our Subjects … to Copy, Epitomize, or Reprint the said Treatises of Navigation … In whole or in part … or to Copy or Counterfeit any of the Maps, Plats or Charts that shall be in the said Treatises, within the them of Thirty years” unless Seller found the derivative work agreeable [Alexander 9]. Such bespoke provisions were the exception rather than the rule; the majority of artists and printers remained vulnerable due to the lack of statutory protection for visual artworks. When Jacob Tonson Sr. reprinted engravings from John Baker’s edition of Hudibras (1710) in his own edition of the same work in the same year, for example, he was only publicly shamed, not legally charged, for the theft [Gómez-Arostegui 1265]. ↩
10. While Hitch v. Langley revolved around the reproduction of image content, both the source and derivative works were published volumes, and as such were protected by the Statute of Anne, which provided copyright protections for printed volumes. While the image content Langley borrowed may have also been protected by Hogarth’s Act, the case citation in the English Reports (22 English Reports 440) does not clarify the statute under which the case was brought. ↩
11. Analyzing images for similar content is a large and well-studied field in computer vision. For a recent survey of the advances convolutional neural networks have made in this field, see Altenberger (2018).
Within the digital humanities, the Visual Geometry Group at Oxford has pioneered the use of the Scale Invariant Feature Transform (SIFT) algorithm to track the reproduction of early modern illustrations (Bergel 2013, Chung 2014), Carl Stahmer has used the Speeded Up Robust Features (SURF) algorithm to study reprintings of early modern ballad woodcuts (Stahmer 2016), Frédéric Kaplan’s digital humanities team at the École polytechnique fédérale de Lausanne has leveraged convolutional neural networks to track reproductions in early renaissance paintings (Seguin 2016), Sabine Lang and Björn Ommer have leveraged edge detection techniques to study similarities between early Christian figural drawings (Lang 2018), and both Peter Bell (Bell 2018) and Leonardo Impett (Impett 2018) have used pose estimation techniques to trace reprinted scenes in Christian iconography and Renaissance Art, respectively. ↩