
The following study leverages several databases of eighteenth-century print culture to reassess the relationship between copyright law and the early English book market. These were turbulent times for the publishing industry, not least because the legal frameworks that governed who could publish and what could be published underwent radical transformations throughout the period. In the late seventeenth century, only members of the London-based Stationers’ Company could publish books or own copyrights. In 1710, the Statute of Anne extended the right to “copy” to all English citizens. Some few decades later in 1741, English Chancery courts created precedent for modern fair use law by ruling that books that derived heavily from others could be found non-infringing in certain cases. Near the end of the century in 1774, English courts legalized a vast public domain of intellectual property by ruling that copyright protections expire a fixed number of years after the initial publication of a work. These and many other legal changes during the eighteenth century created the dynamic foundation on which the modern book market was built.1
This new world of statutory copyright law had a profound influence on the development of the modern author. When eighteenth-century writers and publishers took to the courts to defend the copyright protections they were granted by the 1710 Statute of Anne, they forced English judges to identify exactly what an individual may claim as intellectual property. A series of highly influential cases during the period led judges to identify public matters of fact—such as the names of roads in a British county, or the list of words in the English language—as “unauthored, uncreated ‘facts’ or ‘sources’” [Aoki 26]. Legal scholar Keith Aoki has demonstrated that authors’ attempts to claim copyright control over publications based on these public matters of fact were then “justified or denied on the basis of how much or how little an author-like figure ha[d] intervened, transforming pre-existing raw ‘sources’ and ‘facts’ into something ‘original’” [Aoki 26]. Originality therefore became a fundamental focal point of both literary discourse and copyright disputes in late eighteenth-century England.
Many scholars have traced the ways this legal requirement of “originality” helped transform an Augustan literary culture founded on mimetic imitation into a Romantic literary culture founded on original utterances.2 Benjamin Kaplan, for example, has documented the ways Edward Young’s Conjectures on Original Composition and subsequent proto-Romantic works helped “justify” the foundations of the new statutory copyright law [Kaplan 24]. Peter Jaszi and Martha Woodmansee have elaborated this position, explaining that late-eighteenth century Romantic poets like Wordsworth and Keats believed “genuine authorship is originary in the sense that it results not in a variation, in imitation, or an adaptation, but in an utterly new, unique—in a word, ‘original’—work which, accordingly may be said to be the property of its creator and to merit the law’s protection as such” [Jaszi 195]. Drawing on related insights, scholars including Elizabeth Eisenstein and Jacqueline Rhodes have shown that the imperative of originality in eighteenth-century copyright law helped inspire a form of “possessive individualism” in Romantic literary discourse that “demonised plagiarism,” “valorised individuality,” and helped dedicate Romantic writers to getting their “uniqueness uttered” [Eisenstein 94, Rhodes 4, Waterhouse 40].
If the originality requirement in modern copyright law transformed writing practices, however, so too did the creation of a public commons of intellectual property. Throughout the seventeenth century, copyright ownership was limited to an elite group of sanctioned publishers, and copyright terms never expired. By the end of the eighteenth century, anyone could hold a copyright, and copyright terms expired a maximum of 28 years after the initial publication of a work. These transformations in intellectual property law created a massive public commons of material that was unencumbered by copyright restrictions, and encouraged the rise of a “remix” culture that continues to thrive today. New literary forms such as the “cento”—a pastiche work made of lines from other poets—emerged, and a cottage industry of adaptations, continuations, and reprinted editions arose. Writing before the creation of this literary commons, Daniel Defoe argued “no Man has a Right to make any Abridgement of a Book, but the Proprietor of the Book” [Defoe 20]. Writing in an age of fixed-duration copyright and fair use protections at the end of the century, Fichte would declare “everybody has the right to reprint every book” [Woodmansee 56].
The study below analyzes these and other transformations in eighteenth-century print culture by testing historical hypotheses previous scholars have advanced on the relationship between copyright and print history. The remainder of this chapter discusses the databases leveraged in subsequent chapters and the merits of hypothesis-based humanities research. Chapter Two analyzes the 1710 Statute of Anne’s effect on the geography of printing in Britain. Chapter Three addresses the rise of fair use copyright law and its relationship to derivative artistic practices during the period. Chapter Four examines the establishment of fixed-duration copyright following the 1774 Donaldson v. Beckett case, as well as patterns in book pricing growing out of that landmark decision. Chapter Five concludes the study by summarizing the ways the results below should help inform both the method of future humanities research and our specific understanding of early modern book history.
Databases of Early English Print Culture: ESTC
Arguably the most important resource for the study of books published in the English language before 1800 is the English Short Title Catalogue (ESTC), a public database maintained by the British Library. The ESTC began its life as a digital representation of A. W. Pollard and G. R. Redgrave’s 1926 Short-Title Catalogue of Books Printed in England, Scotland and Ireland … 1475-1640, a thorough bibliographic catalogue of some 35,000 works published in Britain before the English Civil War [Blayney 356]. The ESTC then incorporated Donald Wing’s 1945 Short-Title Catalogue of Books Printed in England … [and] Other Countries, 1641–1700, extending the ESTC’s coverage from the introduction of printing in England through 1700. After combining these foundational bibliographies, Robin Alston and the rest of the ESTC team then partnered with many major cultural heritage institutions—including the National Endowment for the Humanities, the British Library, and over 2,000 partner libraries worldwide—to create The Eighteenth-Century Short-Title Catalog, the world’s first comprehensive bibliographic index of works published between 1700 and 1800. These decades of efforts by thousands of researchers combined to make the ESTC “the largest project ever financed in the field of the humanities,” and arguably the most significant extant database of early English print culture [Veylit 71].
As David McKitterick has written, the ESTC is “a database always under construction” [183], but as of early 2019 the database contained 481,816 records, each of which describes a single work published in Britain or the American Colonies between 1475 and 1800. Each of these records identifies the title, publisher, language, publication location, publication date, and several other descriptive attributes for a given published work. Stephen Tabor, a scholar of book history and contributing ESTC editor, has noted that each of the records in the ESTC is intended to capture the full set of metadata available for a single edition of a published work [Tabor 369]. This metadata has been recorded in Machine Readable Cataloging (MARC) format, and is currently maintained by the University of California, Riverside and the British Library.
While the ESTC has been recognized as “the chief single source of bibliographic information on English printing before 1801” [Tabor 385], it suffers from a number of challenges posed by early modern book history. In the first place, “false imprints,” or deliberately falsified title pages, are a known problem in publications from this period. As early as 1624, the English pamphleteer George Wither complained that printers frequently “publish bookes contriued, altered, and mangled at their owne pleasurs, without consent of the writers … and … change the name someyms, both of booke and Author (after they haue been ymprinted) and all for their owne priuate lucre” [Wither 10-11]. By printing the same book under the names of several different authors and titles, Wither explains, a printer could “take mens moneyes twice or thrice, for the same matter under diuerse names” [121].3 In the eighteenth century, false imprints would also become a favorite tactic of pirate printers who sought to evade copyright restrictions [Lennon 85].4
While false imprints pose a problem for the ESTC database, however, survival rates pose a much greater challenge. In short, the ESTC seeks to represent the full published record of Britain and other English speaking countries before 1800. However, an indeterminate fraction of this early publishing output has completely disappeared from the historical record. Book historian Donald McKenzie has noted that Thomas Dyche’s Guide to the English Tongue was printed in “thirty-three editions and some 275,000 copies between 1733 and 1749,” yet “Only five copies from those editions are known to be extant: a survival rate of one in 55,000” [McKenzie 560]. Analyzing the number of reported copies of ESTC records suggests that the odds of survival were non-uniform among different tranches and periods of the book market:
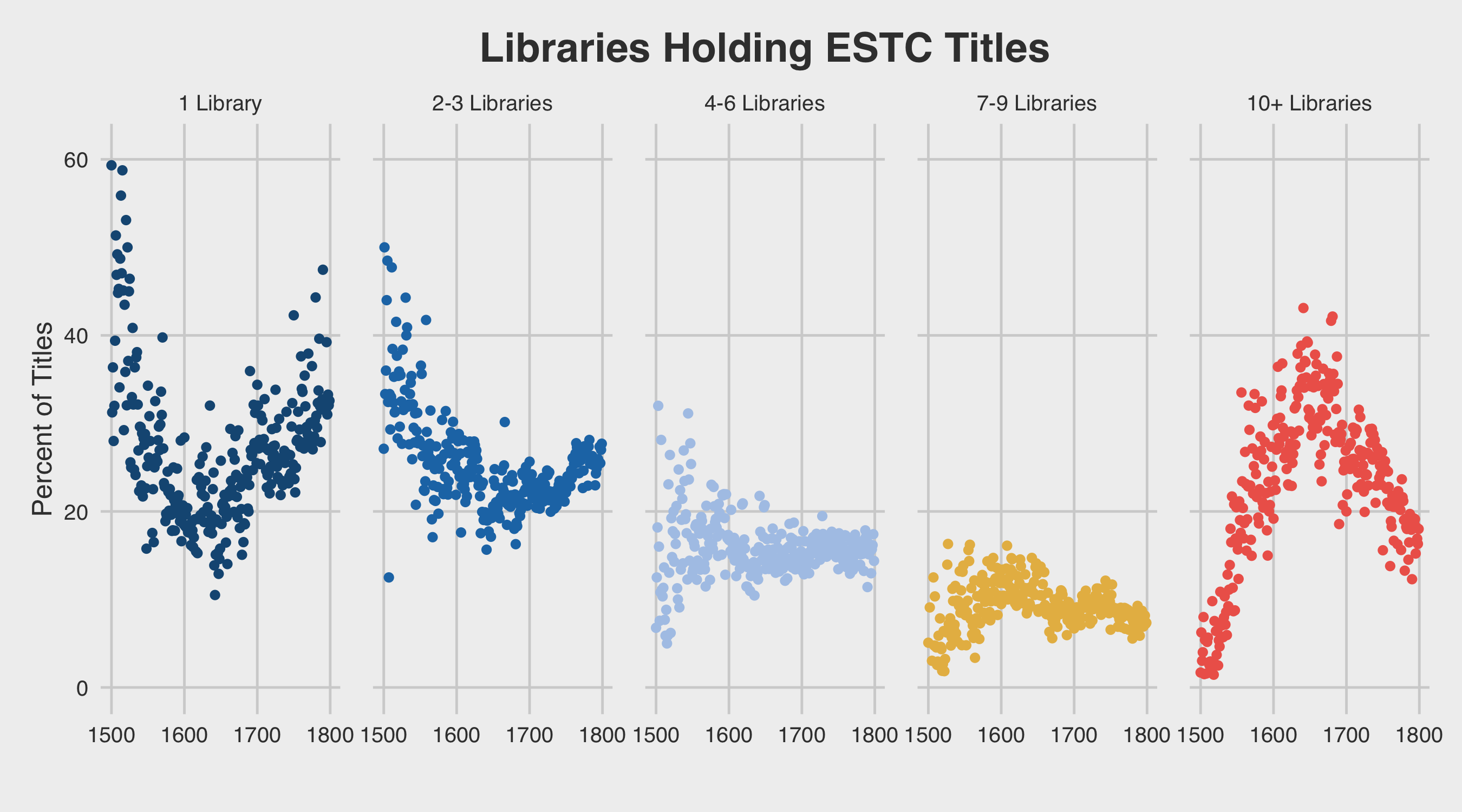
Across the eighteenth century, one finds a steady increase in the number of single-copy records, which poses a fundamental challenge to any quantitative history of the period. These poor odds of survival force researchers to recognize that the ESTC can only ever hope to be a highly representative sample of early book culture; the database will likely never capture the full population of early English print culture.
In addition to the inherent challenges posed by the historical nature of ESTC data, the editors of the database have introduced a number of imperfections as well. As book historian Michael F. Suarez, S.J. has noted, the ESTC does not yet contain a good portion of the surviving pre-1800 printed record. By conducting a thorough analysis of the ESTC’s holdings, Suarez concluded that “as much as 10 per cent of the printed record from 1701-1800 ha[d] not been incorporated into the ESTC” as of 2004 [Suarez 40]. At the same time, Stephen Tabor notes that “witnesses to objects that don’t exist are now frequent in ESTC” [Tabor 372]. More damaging are Peter Blayney’s observations that the ESTC truncates imprints and colophons, was “prepared from microfilm without recourse to actual books,” and contains so many typos that “it is clearly unsafe to trust the old-spelling transcriptions” [Blayney 72]. Tabor has estimated that of the 470,000 records within the ESTC, there are “a minimum of 80,000 records containing at least one error in description,” though he does not describe how he arrived at this figure [Tabor 375]. In the years since these early criticisms were voiced, over ten thousand records have been added to the ESTC, and many records have been thoroughly cleaned up, but the database continues to pose challenges for many researchers.
Despite these difficulties, the ESTC remains the foremost database of early print culture. The archive has been identified as “the largest humanistic research project of the twentieth century” [Korshin 170], and “one of the greatest scholarly ventures ever conducted” [Tanselle xiv]. Even Stephen Tabor, one of the most acute critics of the ESTC, writes that the ESTC is “the fullest and most up-to-date bibliographical account of ‘English’ printing (in the broadest sense) for its first 328 years” [Tabor 367].5
Databases of Early English Print Culture: ECCO
In addition to the ESTC, this study relies heavily on the Eighteenth Century Collections Online (ECCO) databases I and II, a set of 182,765 volumes published between 1700 and 1800 in Britain and the American Colonies. ECCO is the largest organized collection of digitized, full-text records from the eighteenth-century currently available, but as Patrick Spedding has noted, “ECCO’s 32 million pages of text are not a completely representative sample of eighteenth-century publishing” [Spedding 437]. ECCO in fact contains only roughly 60% the eighteenth-century titles in the authoritative ESTC, though the annual title counts in ECCO are strongly correlated with those in the ESTC:

Both ECCO I and II are based on the full-page scans in the 1982 Eighteenth-Century microfilm series and the ESTC. Gale’s offices in Woodbridge, Connecticut sent these microfilm scans to HTC Global Services, Inc. in India, and the latter organization split the microfilm into discrete pages and transformed each page into a large 300 DPI greyscale TIF image. Optical Character Recognition was then run on these page images, and the resulting text was stored in a rich XML markup that includes document-level metadata. Gale’s Connecticut office then ran eight spot checks per page, at a rate of 1 million pages per week, to validate the quality of the digitized surrogate, and unsatisfactory documents were re-processed [Levack 2003]. Collectively, the resulting ECCO I and II databases contain 26 million pages of material, making ECCO by far the largest available archive of early modern print culture.
Like the ESTC, ECCO suffers from a number of historical and technical problems. Patrick Spedding has noted that “Eighteenth-century British printing was often very poor, so errors in transcription may be caused by broken, badly inked, or warped lines of type. There are also problems with the OCR software failing to deal with eccentricities of eighteenth-century type, which includes the long ‘s,’ ligatures, swash capitals, etc.” [Spedding 438]. Spedding also notes that ECCO suffers from a long list of problems that often affect databases based on microfilm sources, including “omitted pages, poor framing and focus, excessive contrast, poorly lit texts, and texts so tightly bound that they cannot be opened fully when filmed” [Spedding 438]. Furthermore, James May notes that ECCO “passes on, often without comment, false claims on title-pages about publishers and places of publication, as well as flimsy conjectures by the original ESTC catalogers about the place and dates of undated works” [May 25]. As we shall see below, the OCR quality and nature of page scans in ECCO have a significant effect on the range of methods that are appropriate for analysis of the ECCO data.
Statistical Analysis Meets Early Modern Studies
While computational methods are still rather foreign to many researchers of the early modern period, scholars have leveraged machine-assisted techniques to study early print culture for several decades now. In her 1978 dissertation Government and the Printing Trade, 1540–1560, Patricia Margaret Took became one of the first researchers to explore the intersection of computational methods and early modern history by aggregating simple counts of the number of publications and printers in England between 1540 and 1560. Took based her counts on Pollard and Redgrave’s 1926 Short Title Catalogue—which researchers around the world were digitizing into the ESTC as Took wrote her dissertation—and she became one of the first to offer a “rough guide to the size and output of the book community” in seventeenth-century England [Took 343]:
The following decade John Feather applied Took’s quantitative method to the largest bibliography of eighteenth-century books available at the time, the four-volume Eighteenth-Century British Books index [ECBB]. The bibliography’s editors assigned each eighteenth-century volume included in the ECBB a Dewey Decimal System subject classification based on the given volume’s title, and Feather analyzed these subject classifications to offer an early “statistical approach to the study of eighteenth-century reading habits” [Feather 46]. Based on this analysis, Feather was able to show that the novel occupied far less of the eighteenth-century book market than scholars following Ian Watt had long believed. Indeed, Feather found that prose fiction occupied a mere 11% of the literary book market, while poetry commanded 47% of the market and was steadily growing at the century’s end [Feather 41-2].
In the 1990’s, Maureen Bell and John Barnard extended these earlier studies by aggregating counts of English publishing across the full temporal range of Pollard and Redgrave’s 1926 Short Title Catalogue. Bell and Barnard’s statistics were computed by hand, as the digitized version of the Short Title Catalogue (soon to be incorporated into the ESTC) was still in active development [Bell 8, 61]. While this early analysis may have been provisional, it clearly demonstrated London’s primacy in the sixteenth-century English book market [Bell 64]. The same team showed that London’s dominance in the printing world continued through the seventeenth century in a subsequent 1998 publication, where they displayed tables of statistics derived from Chadwyck-Healey’s digitized edition of Donald Wing’s Short Title Catalogue [Bell 92].
The first massive quantitative study of early modern culture arrived in Alain Veylit’s 1994 doctoral dissertation, which was founded on analysis of the eighteenth-century records in the English Short Title Catalogue. Although Veylit had become intimately aware of the ESTC’s problems while working as an editor of the database at the University of California in Riverside, he nevertheless believed that “The mass of data contained in the [ESTC] catalog is substantial enough to provide as clear a picture of the overall eighteenth-century production of books and monographs as we will ever get” [Veylit 34]. Veylit attempted to sketch this overall view of the book market by visualizing dozens of distributions within random samples from the ESTC. These plots and tables offered readers some of the first glimpses into many trends in eighteenth-century publishing, including patterns in the sizes, genres, and languages of books published during the period:
In more recent years, a number of researchers have built upon Alain Veylit’s early work to explore latent patterns in the ESTC database. Michael Suarez, for example, has demonstrated that “throughout the [eighteenth] century, more than 80 per cent of surviving titles are between one and ten sheets long,” suggesting the bulk of print output during this period was far shorter than many have suspected [Suarez 60]. The Computational History Group (COMHIS) at the University of Helsinki has also developed a series of tools and studies that analyze massive bibliographical databases such as the ESTC and analogous databases for other periods and countries. In one recent study, the COMHIS group demonstrated that the octavo format became increasingly popular throughout the early modern period in the ESTC, Swedish National Bibliography (SNB), and Heritage of the Printed Book Database (HPBD) [Lahti 2019]:
These previous studies and many others have helped demonstrate the value of quantitative methods in early modern research. The present study seeks to add to this body of scholarship by demonstrating the ways in which additional algorithmic techniques can help improve our understanding of the early English book market.6
Debate-Driven Research in the Humanities
The papers discussed above are part of a growing body of scholarship that critics have referred to variously as cultural analytics, culturomics, cliometrics, computational literary analysis, and most broadly, the digital humanities.7 This collective body of work has recently come under intense scrutiny in both academic literature and the popular press, where critics have argued that computational research in the humanities often fails to provide novel insights into cultural history.8 Nan Da articulates this criticism succinctly: “the problem with computational literary analysis as it stands is that what is robust is obvious … and what is not obvious is not robust” [601]. Da is far from the first to make this claim. When Franco Moretti argued that novel titles grew shorter in the nineteenth century, Adam Kirsch replied: “you hardly need a computer to tell you that: the bulky eighteenth-century title is commonplace and a target of jokes even today” [Kirsch 2014].9 When Hoyt Long and Richard Jean So built a classifier for the haiku form, Timothy Brennan lamented: “After 30 pages of highly technical discussion, the payoff is to tell us that haikus have formal features different from other short poems. We already knew that” [Brennan 2017]. When the Stanford Literary Lab created an algorithm that could identify the genre of novels, Kathryn Schulz responded: “people can do this, too … So what?” [Schulz 2011]. The implicit question in each of these criticisms is one Adam Kirsch has made explicit: “Does the digital component of digital humanities give us new ways to think, or only ways to illustrate what we already know?” [Kirsch 2014].
However, researchers who have tried to show that digital methods give us new ways to think have been dismissed by critics, who argue these more experimental projects do not speak to live research questions in the humanities. When Michael Witmore and Jonathan Hope found that word frequencies could not distinguish the genres of Shakespearean plays, Nan Da dismissed the result, arguing “no one has ever said … word frequency is what distinguishes Shakespeare’s comedies from tragedies” [62]. When Andrew Piper and Richard Jean So failed to find formal differences between MFA writing and mainstream writing, Lincoln Michel replied: “The central question itself is a little bizarre. Who argues that MFA grads write differently from their mainstream literary fiction peers?” [Michel 2016]. According to Timothy Brennan, quantitative studies like these fail to address active questions in the humanities because of a fundamental limitation in research computing itself: “The interpretive problems that computers solve are not the ones that have long stumped critics” writes Brennan; “On the contrary, the technology demands that it be asked only what it can answer, changing the questions to conform to its own limitations” [Brennan 2017].
One way to engage with active questions in the humanities and avoid merely reproducing extant knowledge, the following study suggests, is to bring quantitative evidence to bear on extant scholarly debates. Such debates serve as a helpful entry point for quantitative analysis, as they indicate a genuine area of uncertainty within a research field. By devising quantitative experiments that generate new insights into these debates, one can ensure that the concerns of the humanities do not get lost in digital humanities research. Likewise, one can ensure that no matter the outcome of a digital experiment, at least one side of a debate should be presented with new information.10 More fundamentally, by generating quantitative evidence with which to advance extant debates in the humanities, we can help quantitative and traditional researchers work together to advance our understanding of our common cultural inheritance.
Quantifying the Early Book Trade
The present study leverages new quantitative evidence to reassess a series of pivotal events in eighteenth-century copyright law. The following chapter, The Statute of Anne and the Geography of English Printing, examines the introduction of statutory copyright law in England, a watershed moment in European legal history. In particular, this chapter engages a series of debates over the ways statutory copyright transformed the geography of printing in England. While some scholars claim statutory copyright shattered London’s monopoly on the book market, others argue that members of the London-based Stationers’ Company continued to dominate the English printing industry throughout the century. After examining this debate, the chapter turns to a series of smaller debates concerning pirated books, a publishing trend that grew out of legal conditions established by the Statute of Anne.
The subsequent chapter, Press Piracy from Tonson v. Baker to Cary v. Kearsley, analyzes the rise of “fair use” copyright rulings in English Chancery courts. By analyzing both text reuse and image reuse within 30 million pages of content published in the eighteenth century, this chapter attempts to provide new insights into a scholarly debate over the degree to which fair use case law influenced derivative artistic practices during the period. This chapter then closes by analyzing the derivative artistic practices of John Hamilton Moore, a mariner-turned-printer whose practice of adapting extant sea charts led courts to create fair use law for printed images.
The following chapter, Donaldson v. Beckett and the Cheap Literature Hypothesis, analyzes the introduction of fixed-duration copyright following the landmark Donaldson v. Beckett case (1774). After discussing the historical context of the Beckett case, this chapter turns to the debated “cheap literature hypothesis,” a scholarly argument that maintains the introduction of fixed-duration copyright radically transformed book pricing in late-eighteenth-century England. Scholars who endorse this hypothesis point out that the creation of fixed copyright durations in 1774 instantly placed literary works published before the mid-eighteenth century into a public domain of materials that any publisher could print and sell. The hypothesis goes on to argue that many printers reprinted these public domain works, which caused a surge in supply and corresponding fall in demand for these works. In short, the cheap literature hypothesis argues, the 1774 Donaldson v. Beckett decision allowed a vast number of consumers to purchase and read a collection of cheap, older, out-of-copyright works, thereby establishing the foundations of the English canon.
Finally, this study closes with a concluding chapter that reviews the key findings of the previous chapters before outlining a number of opportunities for future work at the intersections of computational analysis and the early book market. In particular, I address a number of less-known public domain and commercial datasets that could be used to further the study of early modern culture, and ways to extend the analysis conducted in this study forward in history.
Notes
1. For an introduction to eighteenth-century copyright law, see Feather 1987, Rose 1995, and Deazley 2004. On the relationship between the law and literary culture in the eighteenth century, see Feather 1982. For an introduction to the Stationers’ Company and pre-eighteenth-century copyright in England, see Kirschbaum 1946. On the rise of fair use law in the eighteenth century, see Sag 2011. For background on Donaldson v. Beckett and dozens of other pivotal cases from the period, see Bentley 2008. ↩
2. Literary scholars often argue that the eighteenth century witnessed a revolution in notions of authorship, one that moved from a culture based on imitation to a culture organized around the production of original utterances. Since at least the publication of Harold Ogden White’s Plagiarism and Imitation during the English Renaissance, scholars have maintained that those writing in the seventeenth and early eighteenth centuries endorsed the model of imitatio that one finds throughout classical writing. “That early modern writing does not operate according to the logic of original invention is well known,” writes Max Thomas; “Between the residual medieval tradition of compilatio and the humanistic practices of copia and inventio, the dominant structure of writing was largely imitative” [Thomas 282]. By the 1750s, however, the scene had changed. “It is in the middle of the 18th century,” writes George Buelow, that “the concept of originality . . . become[s] [a] significant elemen[t] in critical writings, and it is on this foundation of new ideas that much of the further development of aesthetic criticism as well as actual artistic achievement in all the arts was made possible in the 19th century” [Buelow 123]. During this pivotal period, celebrated works like Edward Young’s “Conjectures on Original Composition” helped make “Originality . . . the main force in the creative process,” driving out earlier endorsements of imitation with an insistence on each author’s individual genius [Buelow 123]. ↩
3. Madeleine Blondel notes that “publishers did not scruple to reprint a book and give it a different title, or simply to change the cover and the title page to give it a new name, so that people might imagine they were reading something new” [529]. Blondel offers a series of examples of this practice: Clara Reeve’s The Phoenix is a reprinting of John Barclay’s Argenis, the anonymous Memoirs of Lydia Tongue-Pad is a recasting of The Lady’s Drawing Room, The History of Sir William Lovedale is a reprinting of The Small-Talker, The History of Charlotte Villars is nearly identical to Injured Innocence, and so on. ↩
4. False imprints are notoriously difficult to identify. Even through detailed manual analysis, they pose “some of the most difficult … problems” eighteenth-century bibliographers have encountered [Ovenden 2010]. Future work that aims to counterbalance the prevalence of false imprints during the period could make use of published bibliographies of false imprints [Weller 1864, Parenti 1951], or attempt to algorithmically identify false imprints by leveraging telltale marks of individual printing presses—such as distinctive cracks [Mann 63] or wormholes [Stahmer 271] in woodcut engravings—within the page scans of eighteenth-century publications. ↩
5. For further background on the ESTC, as well as overviews of the challenges and opportunities the database raises, see in addition to the works above Snyder 1988, Blayney 2007, and Karian 2011. ↩
6. Additional examples of data-driven scholarship on the early English book market may be found in Sutherland 1934, Aspinall 1948, Price 1958, McKenzie 1974, Mitchell 1985, Mitchell 1987, Bland 1999, Dugas 2001, Gants 2002, Raven 2007, and Gael 2014. ↩
7. While these disciplinary terms share a family resemblance, each has its own specific lineage and historic origins. “Cliometrics” began its life as a term for the quantitative study of economic history, but was eventually generalized to refer to quantitative treatments of history more broadly [Anderson 246]. Lev Manovich introduced the phrase “cultural analytics” [Manovich 2007] to describe the research conducted inside the Software Studies Initiative at the University of California, San Diego. “Culturomics” was popularized by the breakout Google Books study by Jean-Baptiste Michel et al. [Michel 2011]. Other terms of art for data-driven research in the humanities include “quantitative formalism” [Allison 2011], “literary analytics” [Clement 2013], “computational criticism” [Moretti 2013], and “computational literary studies” [Da 2019]. ↩
8. It should be noted that many of the critical remarks on digital humanities scholarship cited in the following text and in the professional literature more broadly have been seriously challenged by practitioners within the field. Indeed, many of the technical arguments that motivate Nan Da’s thesis are quite mistaken, as participants in Critical Inquiry’s online forum entitled “Computational Literary Studies: Participant Forum Responses” have recently demonstrated. Nevertheless, critics are quite right to argue that digital humanities scholarship often fails to offer new insights into cultural history. The debate-driven model of scholarship discussed below attempts to resolve this problem. ↩
9. Kirsch could have noted that French literary theorist Gerard Genette’s Paratexts had articulated Moretti’s thesis as early as 1997. “At the beginning of the nineteenth century,” Genette writes, “narrative intertitles (and titles) in the form of summaries or outlines almost entirely died out … in favor of a type of intertitle that is more restrained, or at least shorter, purely nominal, and reduced in most instances to two or three words, or even only one” [Genette 305-306]. While Moretti’s thesis might not be novel, however, he appears to be the first to have demonstrated this point computationally. ↩
10. This debate-based approach to humanities research is motivated in part by the role that counter-example, refutation, and falsification have played within the philosophy of science, where falsificationism is often posited as a philosophical position that avoids many pitfalls in inductive reasoning [Lakatos ]. This philosophy of knowledge grows out of early work by Pierre Duhem [Duhem 187] and Willard Van Orman Quine [Quine 70], and was significantly expanded by Karl Popper in subsequent decades [Popper 23, 70]. For an introduction to this school of philosophy, one could consult the Popper-Kuhn debates, which revolved around the proper interpretation of and reaction to evidence that contradicts the predictions of a formal hypothesis [Kuhn 12]. ↩